Ollama avec iGPU AMD 780m sous Proxmox LXC


Je vais partager mon expérience sur la mise en place d’un hyperviseur avec un processeur mobile Ryzen et son iGPU. J'ai récemment commencé une collection de processeurs mobile Ryzen sous forme de "mini-PC" chinois, commandés notamment sur les grosses plateformes d'e-commerce (Aliexpress, Geekbuying, etc.), ceci en vue de monter des hyperviseurs très performants tout en limitant la consommation électrique.
La documentation pour la mise en place d’un tel système est facilement accessible, donc je vais essayer d’être bref et direct dans ce post. Tout d'abord, il n'est pas nécessaire d'installer les pilotes Radeon d'AMD sur l'hyperviseur, puisque le noyau contient déjà tout ce dont vous avez besoin.
Cependant, pour profiter pleinement des performances de votre iGPU, il faudra recompiler le noyau. Le problème est que la version par défaut inclut un patch qui n'est pas dans la branche principale du code source, et qui permet d'améliorer considérablement l'étanchéité globale lors de l'utilisation de l'augmentation dynamique de la mémoire du GPU.
Pour compiler le noyau en toute simplicité, je vous recommande de partir du projet kernel officiel de Proxmox. Cela vous permettra d’inclure tous les patchs de la team Proxmox et donc de bénéficier des améliorations de stabilité et de performance apportées par la team.
Dépôt en lecture seule (clone de l'orignal)
git clone https://github.com/proxmox/pve-kernel
cd pve-kernel
apt update
apt install devscripts
apt install dh-make
make build-dir-freshPour continuer avec la compilation et la mise en place de votre système, il faut ajouter un patch dans le dossier approprié (dans le projet kernel officiel de Proxmox, c'est généralement pve-kernel/patches/kernel) selon la version que vous utilisez. Pour ma part, j’utilise la version 6.14, mais comme mentionné plus haut, je l'ai un peu personnalisée pour l'ajuster pour mon système.
6.14 :
From: Mika Laitio @ 2024-11-27 11:46 UTC (permalink / raw)
To: christian.koenig, Xinhui.Pan, airlied, simona, Hawking.Zhang,
sunil.khatri, lijo.lazar, kevinyang.wang, amd-gfx, dri-devel,
linux-kernel, lamikr
AMD gfx1103 / M780 iGPU will crash eventually when used for
pytorch ML/AI operations on rocm sdk stack. After kernel error
the application exits on error and linux desktop can itself
sometimes either freeze or reset back to login screen.
Error will happen randomly when kernel calls evict_process_queues_cpsch and
restore_process_queues_cpsch methods to remove and restore the queues
that has been created earlier.
The fix is to remove the evict and restore calls when device used is
iGPU. The queues that has been added during the user space application execution
time will still be removed when the application exits
On evety test attempts the crash has always happened on the
same location while removing the 2nd queue of 3 with doorbell id 0x1002.
Below is the trace captured by adding more printouts to problem
location to print message also when the queue is evicted or resrored
succesfully.
[ 948.324174] amdgpu 0000:c4:00.0: amdgpu: add_queue_mes added hardware queue to MES, doorbell=0x1202, queue: 2, caller: restore_process_queues_cpsch
[ 948.334344] amdgpu 0000:c4:00.0: amdgpu: add_queue_mes added hardware queue to MES, doorbell=0x1002, queue: 1, caller: restore_process_queues_cpsch
[ 948.344499] amdgpu 0000:c4:00.0: amdgpu: add_queue_mes added hardware queue to MES, doorbell=0x1000, queue: 0, caller: restore_process_queues_cpsch
[ 952.380614] amdgpu 0000:c4:00.0: amdgpu: remove_queue_mes removed hardware queue from MES, doorbell=0x1202, queue: 2, caller: evict_process_queues_cpsch
[ 952.391330] amdgpu 0000:c4:00.0: amdgpu: remove_queue_mes removed hardware queue from MES, doorbell=0x1002, queue: 1, caller: evict_process_queues_cpsch
[ 952.401634] amdgpu 0000:c4:00.0: amdgpu: remove_queue_mes removed hardware queue from MES, doorbell=0x1000, queue: 0, caller: evict_process_queues_cpsch
[ 952.414507] amdgpu 0000:c4:00.0: amdgpu: add_queue_mes added hardware queue to MES, doorbell=0x1202, queue: 2, caller: restore_process_queues_cpsch
[ 952.424618] amdgpu 0000:c4:00.0: amdgpu: add_queue_mes added hardware queue to MES, doorbell=0x1002, queue: 1, caller: restore_process_queues_cpsch
[ 952.434922] amdgpu 0000:c4:00.0: amdgpu: add_queue_mes added hardware queue to MES, doorbell=0x1000, queue: 0, caller: restore_process_queues_cpsch
[ 952.446272] amdgpu 0000:c4:00.0: amdgpu: remove_queue_mes removed hardware queue from MES, doorbell=0x1202, queue: 2, caller: evict_process_queues_cpsch
[ 954.460341] amdgpu 0000:c4:00.0: amdgpu: MES failed to respond to msg=REMOVE_QUEUE
[ 954.460356] amdgpu 0000:c4:00.0: amdgpu: remove_queue_mes failed to remove hardware queue from MES, doorbell=0x1002, queue: 1, caller: evict_process_queues_cpsch
[ 954.460360] amdgpu 0000:c4:00.0: amdgpu: MES might be in unrecoverable state, issue a GPU reset
[ 954.460366] amdgpu 0000:c4:00.0: amdgpu: Failed to evict queue 1
[ 954.460368] amdgpu 0000:c4:00.0: amdgpu: Failed to evict process queues
[ 954.460439] amdgpu 0000:c4:00.0: amdgpu: GPU reset begin!
[ 954.460464] amdgpu 0000:c4:00.0: amdgpu: remove_all_queues_mes: Failed to remove queue 0 for dev 5257
[ 954.460515] amdgpu 0000:c4:00.0: amdgpu: Dumping IP State
[ 954.462637] amdgpu 0000:c4:00.0: amdgpu: Dumping IP State Completed
[ 955.865591] amdgpu: process_termination_cpsch started
[ 955.866432] amdgpu: process_termination_cpsch started
[ 955.866445] amdgpu 0000:c4:00.0: amdgpu: Failed to remove queue 0
[ 956.503043] amdgpu 0000:c4:00.0: amdgpu: MES failed to respond to msg=REMOVE_QUEUE
[ 956.503059] [drm:amdgpu_mes_unmap_legacy_queue [amdgpu]] *ERROR* failed to unmap legacy queue
[ 958.507491] amdgpu 0000:c4:00.0: amdgpu: MES failed to respond to msg=REMOVE_QUEUE
[ 958.507507] [drm:amdgpu_mes_unmap_legacy_queue [amdgpu]] *ERROR* failed to unmap legacy queue
[ 960.512077] amdgpu 0000:c4:00.0: amdgpu: MES failed to respond to msg=REMOVE_QUEUE
[ 960.512093] [drm:amdgpu_mes_unmap_legacy_queue [amdgpu]] *ERROR* failed to unmap legacy queue
[ 960.785816] [drm:gfx_v11_0_hw_fini [amdgpu]] *ERROR* failed to halt cp gfx
Signed-off-by: Mika Laitio <[email protected]>
---
.../drm/amd/amdkfd/kfd_device_queue_manager.c | 24 ++++++++++++-------
1 file changed, 16 insertions(+), 8 deletions(-)
diff --git a/drivers/gpu/drm/amd/amdkfd/kfd_device_queue_manager.c b/drivers/gpu/drm/amd/amdkfd/kfd_device_queue_manager.c
index c79fe9069e22..96088d480e09 100644
--- a/drivers/gpu/drm/amd/amdkfd/kfd_device_queue_manager.c
+++ b/drivers/gpu/drm/amd/amdkfd/kfd_device_queue_manager.c
@@ -1202,9 +1202,12 @@
struct kfd_process_device *pdd;
int retval = 0;
+ // gfx1103 APU can fail to remove queue on evict/restore cycle
+ if (dqm->dev->adev->flags & AMD_IS_APU)
+ goto out;
dqm_lock(dqm);
if (qpd->evicted++ > 0) /* already evicted, do nothing */
- goto out;
+ goto out_unlock;
pdd = qpd_to_pdd(qpd);
@@ -1213,7 +1216,7 @@
* Skip queue eviction on process eviction.
*/
if (!pdd->drm_priv)
- goto out;
+ goto out_unlock;
pr_debug_ratelimited("Evicting PASID 0x%x queues\n",
pdd->process->pasid);
@@ -1248,8 +1251,9 @@
KFD_UNMAP_QUEUES_FILTER_DYNAMIC_QUEUES, 0,
USE_DEFAULT_GRACE_PERIOD);
-out:
+out_unlock:
dqm_unlock(dqm);
+out:
return retval;
}
@@ -1262,7 +1266,7 @@
struct kfd_process_device *pdd;
uint64_t pd_base;
uint64_t eviction_duration;
- int retval, ret = 0;
+ int retval, ret=0;
pdd = qpd_to_pdd(qpd);
/* Retrieve PD base */
@@ -1343,14 +1347,18 @@
uint64_t eviction_duration;
int retval = 0;
+ // gfx1103 APU can fail to remove queue on evict/restore cycle
+ if (dqm->dev->adev->flags & AMD_IS_APU)
+ goto out;
+
pdd = qpd_to_pdd(qpd);
dqm_lock(dqm);
if (WARN_ON_ONCE(!qpd->evicted)) /* already restored, do nothing */
- goto out;
+ goto out_unlock;
if (qpd->evicted > 1) { /* ref count still > 0, decrement & quit */
qpd->evicted--;
- goto out;
+ goto out_unlock;
}
/* The debugger creates processes that temporarily have not acquired
@@ -1381,7 +1389,7 @@
if (retval) {
dev_err(dev, "Failed to restore queue %d\n",
q->properties.queue_id);
- goto out;
+ goto out_unlock;
}
}
}
@@ -1392,8 +1400,10 @@
atomic64_add(eviction_duration, &pdd->evict_duration_counter);
vm_not_acquired:
qpd->evicted = 0;
-out:
+
+out_unlock:
dqm_unlock(dqm);
+out:
return retval;
}
6.12 : ici.
make debAprès il suffit d'installer les paquetages deb (AMD64) générés et de rebooter le noeud PVE.
Pour le conteneur LXC on va utiliser ce script (préférer Ubuntu 24.04 à l'install car ROCm est mieux supporté) :
Script pour installer Open WebUI
Ce script installe Open WebUI facilement sous forme de conteneur LXC. Par défaut 4Go de RAM peut être intéressant car l'iGPU possède une mémoire extensible (par défaut la moitié de la RAM disponible sur la machine).On peut par exemple laisser la VRAM dans le Bios à 1Go. Il ne faut pas installer le paquetage Ollama. On va l'installer sous forme de conteneur (Podman ou Docker).
Avant d'installer Ollama il est nécessaire de "forwarder" dans le conteneur LXC, la carte graphique. Pour cela il faut modifier le fichier de configuration du conteneur LX qui se trouve ici : /etc/pve/lxc. Il faut ajouter ces lignes dans le fichier de configuration (et redémarrer le conteneur) :
dev0: /dev/dri/card0,gid=44
dev1: /dev/dri/renderD128,gid=104
dev2: /dev/kfd,gid=104Ensuite il va falloir faire confiance aux différents fork d'Ollama, qui sont tunés pour accepter la mémoire extensible de la carte graphique (GTT) qui a été implémenté (encore de manière maladroite) dans les dernières versions du noyau.
Et pour cela il suffit de faire confiance à ce projet (et, oui, il y en a d'autres...) :
Voilà la ligne de commande que j'ai utilisé pour démarrer le conteneur (c'est possible de le faire avec podman mais en mode privilégié - comme sur la doc officielle) :
docker run --name ollama -v /opt/ollama/:/root/.ollama:Z -e OLLAMA_FLASH_ATTENTION=true -e HSA_OVERRIDE_GFX_VERSION="11.0.2" -e OLLAMA_KV_CACHE_TYPE="q8_0" --device /dev/kfd --device /dev/dri -e OLLAMA_DEBUG=0 -p 127.0.0.1:11434:11434 ghcr.io/rjmalagon/ollama-linux-amd-apu:latest serve
docker update --restart always ollama
docker start ollamaNote : La variable HSA_OVERRIDE_GFX_VERSION="11.0.2" est nécessaire il permet de faire correspondre le GPU à un typologie précise (RDNA3).
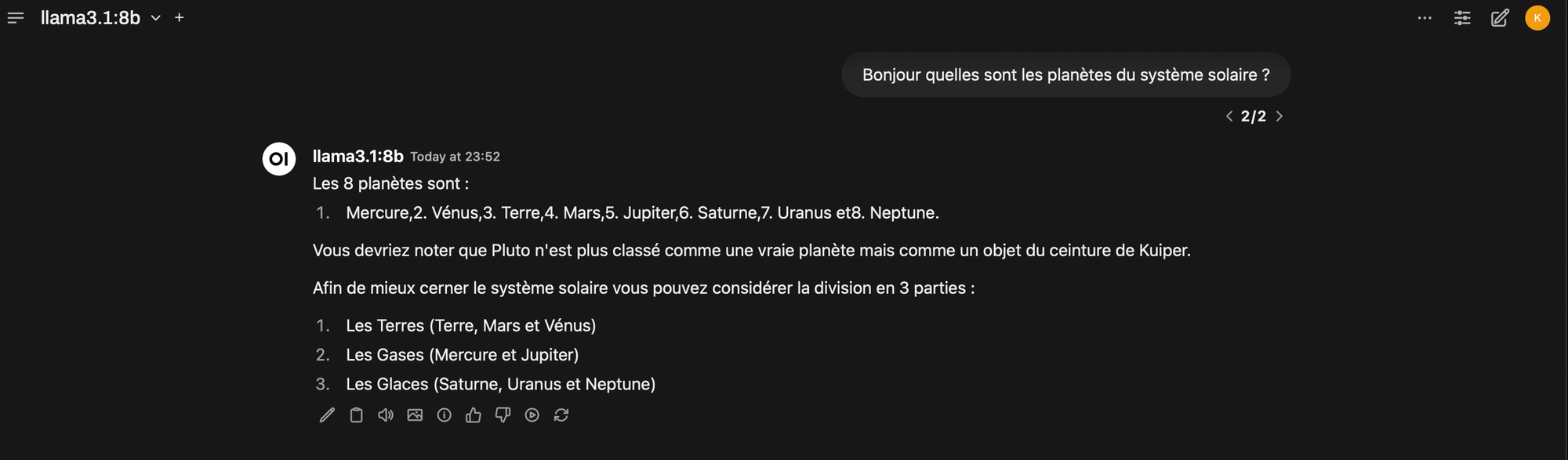
Normalement à ce stade tout devrait être fonctionnel. Les plus gros modèles devraient avoir encore des problèmes (cela dépend de la mémoire accessible) mais les modèles plus moyens et petits, devront répondre assez rapidement (une fois le chargement effectué par Ollama). Pour tester tout cela de manière simple il suffit d'utiliser Open WebUI à l'adresse du conteneur LXC sur le port 8080. Ce sera sensiblement pareil que l'utilisation des cores CPU, mais si vous avec Proxmox sur votre machines ces cores seront plus efficaces à faire d'autres choses.
Pour valider que c'est bien le GPU qui prend la charge il suffit d'installer radeontop sur l'hyperviseur.
Bonne utilisation raisonnée de vos ressources... et à bientôt...
